
At the end of June 2006 I was very excited about my upcoming trip: my first trip to Spain (and my first swim in the Mediterranean). I was going to the Guadec Conference in Vilanova i la Geltrú! I thought I would be able to speak a little with the local people as I had recently started some Spanish evening classes.
The conference was well-attended and well-organised, and of course there were a few long nights dedicated to networking (which is really a synonym for “enjoying the speciality of the area with friends” or, should I say, “boozing on the local beer”).


The traditional conference dinner/evening was organised as a BBQ and disco on the beach – great idea! I then realised how much I’d missed hot days and nights.


On the last day I had time to eat my last Spanish sandwich while sitting on a bench on one of the nice, busy streets of Vilanova before I took the train to the airport. The sandwich was not particularly hard but I still managed to break a tooth (more on this on my next post).
 Then an old man came and sat next to me. Great! At long last I would be able to try my Spanish. Until now English was de rigueur. He started to talk but I could not understand a word – so much for those Spanish lessons, I thought. It took me a while to remember that Vilanova is in Catalonia. They speak in Catalan, which is rather different from Spanish. After a few verbal attempts we started communicating with gestures. I tried to tell him that I was flying out to Sofia, pretending to be a flying plane like kids do. I will never know if he understood me or if he still thinks of the time he met a completely mad woman. For me it was a charming encounter that made me believe that people can understand each other without words, without fear – something that we should all believe in given the tense atmosphere of 2016.
Then an old man came and sat next to me. Great! At long last I would be able to try my Spanish. Until now English was de rigueur. He started to talk but I could not understand a word – so much for those Spanish lessons, I thought. It took me a while to remember that Vilanova is in Catalonia. They speak in Catalan, which is rather different from Spanish. After a few verbal attempts we started communicating with gestures. I tried to tell him that I was flying out to Sofia, pretending to be a flying plane like kids do. I will never know if he understood me or if he still thinks of the time he met a completely mad woman. For me it was a charming encounter that made me believe that people can understand each other without words, without fear – something that we should all believe in given the tense atmosphere of 2016.
As you know I have been on the conference circuit for a number of years. Through those years I have collected some wonderful anecdotes.
I cannot remember the year or the place but it was definitely somewhere in the North of England where a UKUUG (as it was known then) meeting took place. Everything was going very well, the talks were good and the conference was well attended. The organisers had arranged for a buffet lunch so you can well imagine the queue to get to the food. As I was invited and did not pay for my lunch, I thought I should go at the end of the queue, hoping they would leave me some of the beautiful salads and desserts.
I am happily waiting at the back of the room when I felt somebody’s arm around my shoulder. I looked up and saw the organiser who then said:
Look at them all: they all have Asperger’s, you and I Alzheimer’s.
Asperger’s and Alzheimer’s are very serious conditions and no laughing matter but I still cannot stop giggling when I think of this comment.

The next Spring conference will be held in Manchester, March 14th to 16th 2017.
On the outside large brick wall, you are greeted with:
With freedom, books, flowers and the moon, who could not be happy?
– a famous quote from De Profundis by Oscar Wilde, written in very large letters. This sets the atmosphere to the visit.
HMP Reading opened in 1844. It was one of the first new prisons using the cruciform design – long wings of cells stretching out from a central point which allowed the guards to oversee each wing on all floors. Recently the prison housed young offenders (18 to 21 years old). Up to three offenders were kept in one cell when the crime rate spiked. The prison was shut in 2013 and has been kept empty since, costing a great amount of money for its upkeep. As a Grade II-listed building, it is not saleable.
The prison comprises 3 floors – 1st: green, 2nd: red and 3rd: blue. Not only is the door painted in the appropriate colour but so are the bed frames, metal tables and stools that are screwed onto the wall and floor.

From floor 1 to 2 and more

One wing on Floor 3

Prison humour
Oscar Wilde was housed in cell C.3.3 (which became C.2.2 when the numbering system was changed). The cell is completely empty as many more prisoners have been kept in there. During the first three months of incarceration he was allowed only three books – the bible, a prayer book and a hymn book. After that he was allowed to choose one book a week from the prison library. Eventually, he was allowed to receive books from outside so long they were vetted. These books can be found in the neighbouring cells – a nice but rather small collection. The following quote spells out his state of mind:
“In the great prison where I was then incarcerated, I was merely the figure and the letter of a little cell in a long gallery, one of a thousand lifeless numbers as of a thousand lifeless lives.” – De Profundis, 1897.

Cell C.2.2. was C.3.3.

Cell C.2.2. or Oscar Wilde cell
Many artists were invited to show their work for an exhibition which takes place in cells randomly chosen on the three floors. Doris Salcedo presents “Plegaria Muda” (Silent Prayer). The tables, roughly the size of a coffin, are made of wood and compacted earth. My first feeling was doom and pain, until I saw some green grass growing through the planks – then I thought of hope.

Death or

Hope?
Other artists include
- Marlene Dumas with her portraits of Oscar Wilde, Bosie and Jean Genet
- Nan Goldin: The Boy, sequences of Salomé. She video interviewed a 91-year-old man who is still campaigning for an apology from the government for his conviction for homosexuality 70 years ago.
- Wolfgang Tillmans
- Peter Dreher
- Roni Horn
- Felix Gonzales-Torres
- Steve McQueen
- Robert Gober
Writing by Ai Weiwei, Tahmima Anam, Deborah Levy, Gillian Slovo, Binyavanga Wainaina. Danny Morrison (Secretary of the Bobby Sand Trust) and many more are displayed on the cell’s tables. You can either read the papers or listen to the audio.
Contemporary history is also represented with aerial drawings of the H-Block of Long Kesh by Rita Donagh and two paintings by Richard Hamilton based on the blanket protest and the first H-Block hunger strike.
It is sad that the Reading Gaol, as it was known then, was made famous by Oscar Wilde for a crime no longer considered a crime. So how many people are in jail now for actions that will be legalised in 20 years or more?
A year ago I was still working, going to all kind of techie conferences and meeting all the friends I made during my time at O’Reilly and 2nd Quadrant. Today things are completely different: I am learning to stay at home (a very difficult learning curve). I very often feel like a headless chicken. Being retired, I have no structure to my day – it feels that I have got all the time in the world to accomplish nothing and that’s what happened: I accomplished nothing. I suppose that’s OK for a few months, but I did not want my life to be without an aim, with nothing to do except dusting (which I am pretty bad at).
What do I do?
- Piano: my daughter is teaching me. I have to get used to C, D, E etc. instead of the missed Do, Re, Mi … I am slowly getting there and the very abridged version of “Ode to Joy” is becoming a ‘joy’ to play.
- Allotment: I have a small plot in the village where I grow lots of courgettes. My courgette cake is a well-recognised and liked cake among my neighbours.
- Yoga: Once a week I go for a stretch at the local school.
- I also tried to learn Spanish but the local language school is no longer providing adult tuition so back to Duolingo on my phone. Better than nothing I suppose.
- Dog walking: every weekday, I help a neighbour walking her dogs (she has 11 German Spitzes and one Chow – I have got only Deegan and he is the best).

Going for a walk

Resting in the sun
But I need more:
Today I joined U3A – yes, you guessed it, this is the University of the Third Age. Please laugh quietly as it is very upsetting to know that one is old. What will I do there? I am opting for something practical and hopefully I will find something good for my brain.
I hope there is enough variety to keep me amused and sane.
PGDay UK took place at 30 Euston Square on July 7th. The location is perfect as it’s easy to get to via underground, buses or trains.
After the usual registration, refreshments, welcome and introductions came the long-awaited talk “Working in Open Source” by Liam Maxwell, CTO for Her Majesty’s Government. This talk was followed by Magnus Hagander, President of PostgreSQL Europe, who alerted us to the new key features of the next release which is now available in alpha and soon to be available in beta before the final version is released towards the end of the year. Some new key features include:

Magnus Hagander – New features
“Upsert” (INSERT … ON CONFLICT): 5 brings support for “UPSERT” operations.
BRIN (Block Range Indexes): BRIN stands for Block Range INdexes, and store metadata on a range of pages. At the moment this means the minimum and maximum values per block.
pg_rewind: pg_rewind makes it possible to efficiently bring an old primary in sync with a new primary without having to perform a full base backup.
Import Foreign Schema: with PostgreSQL 9.5, you can import tables en masse. You can also filter out any tables you don’t wish or limit it to just a specific set of tables
Inheritance with foreign table: Foreign tables can now either inherit local tables, or be inherited from.
David Kennaway showed us the challenges presented in a financial services environment and how PostgreSQL fits into the strategy at Goldman Sachs.
Mike Lujan from Manchester University talked to us about the AXLE project… but what is the AXLE project? AXLE, advanced analytics for extremely large European databases, brings together a diverse group of researchers covering hardware, database kernel and visualisation all focused on solving the needs of extremely large data analysis. The project partners are 2ndQuadrant, Barcelona Supercomputing Center, Portavita, the University of Ljubljana and the University of Manchester. The project, like PostgreSQL, is of course Open Source.
With “PostgreSQL Back Up and Recovery: Best practices and tools” by Devrim Gunduz, we discovered solutions for common issues along with pros and cons for each of them. There are of course many backup solutions – both open and closed source.
Gianni Ciolli gave us some “PostgreSQL Administration Recipes”. These recipes should enhance the user’s experience of PostgreSQL by making it speedier and more effective.
Marco Slot discussed the internals and performance of pg_shard and some of its latest features. pg_shard is a free, open source extension for scaling out PostgreSQL across a cluster of commodity servers.
In his “Fun Things to Do with Logical Decoding” Mike Fowler looked at trigger-less auditing, partial replication and full statement replication. Was that fun? I am not so sure!
The next talk had a great title – “The Elephant and the Snake” – could it be a story by Rudyard Kipling or one of Aesop’s fables? No, but Tony Locke told us how to connect from Python to PostgreSQL, including tips and tricks.

Simon Riggs: The Future
The day ended with a plea from Simon Riggs for users to upgrade and test the new 9.5 release to ensure the version is bug-free, helping the PostgreSQL community currently working on the 9.6 release and beyond.
With around 100 people attending the conference, PGDay UK 2015 was one of the most dynamic PosgreSQL meetings that I have ever attended. The audience was very diverse, coming from universities, big corporations, small companies and government institutions.
Thanks to the sponsors 2ndQuadrant, EDB, Brandwatch and CitusData, we were provided with good food and a drink reception at the end of the day.
Interested in PostgreSQL? Why not come to the PostgreSQL conference Europe 2015, which will take place in Vienna on October 27th to 30th? Hope to see you there!
A few weeks ago, I received the most wonderful email – an invitation to attend Pycon Sei in Florence. Who could refuse such an invitation – not me for sure!




Florence, the cradle of the Renaissance, home to some of the most classical maestros: Leonardo da Vinci, Michelangelo, Botticelli, Giotto, Masaccio. Florence where you discover the most beautiful buildings: Palazzo Vecchio, Palazzo Pitti, Ponte Vecchio, il Duomo, Santa Croce, San Miniato. At every street corner, you discover some wonderful sights – a statue, a building, a view on the Arno, a look at the street market (mainly leather goods). I could spend weeks there enjoying the views, the food and going mad at the number of tourists! Unfortunately Florence is loved by many people and sometime you feel that you are not going where you want to but you are carried somewhere.
 In Italy the Pycon meetings started in 2007 in the centre of Florence and continued until Pycon Quattro – I fell in love with Florence during Pycon Due when Richard Stallman gave a talk at the Palazzo Vecchio. In 2011, Florence held EuroPython – a partnership that lasted 3 years (pretty good when EuroPython had to move on to another city after 2 years). Unfortunately the hotel in the centre could not cope with 1000 delegates and the conference was moved to the Grand Hotel Mediterraneo, a few yards from the Arno and almost opposite to the Piazzale Michelangelo. 2014 saw the return of Pycon with Pycon Cinque. During that year, the Associazione Python Italia with Tinker Garage also organized Django Village. For 2015, they decided to combine the two conferences and produced Pycon Sei with a minimum of 4 tracks: Python, Django, PyData and Odoo. Two training tracks were sometimes added to the schedule. They were: Introduzione a Genropy with Giovanni Porcari; Building an Interpreter in RPython with Julian Berman; Creare la propria PaaS (Platform as a Service) con uwsgi.it with Roberto De Ioris and OOP: Object-Oriented Python partendo da zero with Leonardo Giordani.
In Italy the Pycon meetings started in 2007 in the centre of Florence and continued until Pycon Quattro – I fell in love with Florence during Pycon Due when Richard Stallman gave a talk at the Palazzo Vecchio. In 2011, Florence held EuroPython – a partnership that lasted 3 years (pretty good when EuroPython had to move on to another city after 2 years). Unfortunately the hotel in the centre could not cope with 1000 delegates and the conference was moved to the Grand Hotel Mediterraneo, a few yards from the Arno and almost opposite to the Piazzale Michelangelo. 2014 saw the return of Pycon with Pycon Cinque. During that year, the Associazione Python Italia with Tinker Garage also organized Django Village. For 2015, they decided to combine the two conferences and produced Pycon Sei with a minimum of 4 tracks: Python, Django, PyData and Odoo. Two training tracks were sometimes added to the schedule. They were: Introduzione a Genropy with Giovanni Porcari; Building an Interpreter in RPython with Julian Berman; Creare la propria PaaS (Platform as a Service) con uwsgi.it with Roberto De Ioris and OOP: Object-Oriented Python partendo da zero with Leonardo Giordani.

Alex Martelli

Gabriele Bartolini
Lots of the talks were in English. My favourite speaker, Alex Martelli (Google), started the day with Modern Python patterns and idioms first in Italian and later on in English – I do not understand Italian nor Python but to see Alex’s passion is pure magic – all of his body is moving. He is the epitome of Italians, the way we like them and sometime make gentle fun of them. I must admit that his English version of the same talk is not as dramatic, at least not for the technophobe as my admiration is just about the show, the sound, the music. Other good presentations included Asynchronous Web Development with Python 3 by Anton Caceres; PostgreSQL 9.4 for Devops by Gabriele Bartolini; Odoo disaster recovery con Barman by Giulio Calacoci; Does Python stand a chance in today’s world of data science by Radim Rehurek; Packaging Django projects for PyPI by Roberto Rosario and many more.
Saturday saw a recruiting session – it was very interesting to see the different ways that companies will entice new recruits. It went from the big PR spiel to the down to earth approach: that’s the job, that’s what we want from you, that’s what you get from us. Companies hiring are: InfoCert; Zalando, Kuldat, Develer; 2ndQuadrant.
There are no techie conferences without networking and the first event was PyBeer on Friday which took place at the James Joyce Pub. This was an occasion to relax and enjoy the time together drinking, chatting and actually learning to know each other as Pythonistas. To consolidate our new friendships, on Saturday we met at the Ristorante Zazà for PyFiorentina. There you can taste the famous bistecca alla fiorentina – a T-bone steak grilled over a wood or charcoal fire, to be eaten with a glass of wonderful Italian red wine. Just delicious!
Pycon Italy is organized by the Associazione Python Italia but I know that Develer srl spend a lot of time and resources putting the show together. You can find this lovely company between Prato and Florence. They boost of being a team of developers and design engineers who average age is just over 30 years. All Develeriani are selected through accurate tests and constantly trained to provide the most innovative technologies.

NV: Does the dependency free nature of Mojolicious act as an invitation to people familiar with other frameworks (i.e. Ruby on Rails) and languages (i.e. PHP)? That aside, what other factors/features would lure such developers to the framework?
SR: The dependency free nature of Mojolicious is actually more of a myth, the truth is that installing Mojolicious is simply a very fast and pleasant experience.
One of the ways in which we’ve done this, is to make hard to install 3rd party modules like IO::Socket::SSL and Net::DNS::Native optional.
I think what makes Mojolicious special is best explained with an example application:
use Mojolicious::Lite;
use 5.20.0;
use experimental 'signatures';
# Render template "index.html.ep" from the DATA section
get '/' => {template => 'index'};
# WebSocket service used by the template to extract the title from a web site
websocket '/title' => sub ($c) {
$c->on(message => sub ($c, $msg) {
my $title = $c->ua->get($msg)->res->dom->at('title')->text;
$c->send($title);
});
};
app->start;
__DATA__
@@ index.html.ep
% my $url = url_for 'title';
<script>
var ws = new WebSocket('<%= $url->to_abs %>');
ws.onmessage = function (event) { document.body.innerHTML += event.data };
ws.onopen = function (event) { ws.send('http://mojolicio.us') };
</script>
This is actually the first example application you encounter on our website (http://mojolicio.us).
It doesn’t look very complicated at all. But once you start digging a little deeper, you’ll quickly realize how crazy (in a good way) it really is, and how hard it would be to replicate with any other web framework, in any language.
To give you a very quick summary:
- There’s an EP (Embedded Perl) template, in the DATA section of a single-file web application. That template generates an HTML file, containing JavaScript, which opens a WebSocket connection, to a dynamically generated URL (ws://127.0.0.1:3000/title), based on the name of a route.
- Then sends another URL (http://mojolicio.us) through the WebSocket as a text message, which results in a message event being emitted by the server.
- Our server then uses a full featured HTTP user agent, to issue a GET request to this URL, and uses an HTML DOM parser to extract the title from the resulting document with CSS selectors.
- Before finally returning it through the WebSocket to the browser, which then displays it in the body of our original HTML file.
Next year at Mojoconf 2015, I’ll be giving a whole talk about this one application, exploring it in much greater detail.
NV: It’s a framework that you use in pure Perl. Why not go for a DSL like Dancer does?
SR: There are actually two kinds of web framework DSLs, and they differ by scope.
First, you have your routing DSL, which usually runs during server start-up and modifies application state. (application scope)
get '/foo' => sub {...};
Second, there is what I would call the content generation DSL, which modifies request/response state. (request scope)
get '/foo' => sub {
header 'Content-Type' => 'text/plain';
render 'some_template';
};
Mojolicious does have the first kind, and we’ve already used it in the examples above, but not the second. And the reason for this, is that the second kind does not work very well, when you plan on handling multiple requests concurrently in the same process, which involves a lot of context switching. It’s a trade-off between making your framework more approachable for beginners, that might not know Object-Oriented Perl yet, and supporting modern real-time web features.
Which object system is Mojolicious using and which can I use in my code?
Mojolicious uses plain old hash-based Perl objects, and we take special care to allow for Moose and Moo to be used in applications as well.
NV: With Dancer you can easily integrate jQuery and Bootstrap with the templating system. How does Mojolicious approach this integration?
Mojolicious is completely JavaScript/HTML/CSS framework agnostic, and will work with all of them. Some frameworks, including jQuery and Bootstrap, do have plugins on CPAN, but we don’t discriminate.
NV: Mojolicious vs Mojolicious::Lite. When to use each?
SR: I usually start exploring ideas with a single-file Mojolicious::Lite prototype, like we’ve seen above, and slowly grow it into a well-structured Mojolicious web application, which looks more like your average CPAN distribution.
This is a rather simple process, because Mojolicious::Lite is only a tiny wrapper around Mojolicious, and both share like 99% of the same code.
NV: What can we expect in the future and what is the greater vision for the project’s evolution?
Mojolicious has an amazing community, and I hope we can expand on that to reach more people from outside the Perl community in the future. Not a day goes by where I don’t receive requests for a Mojolicious book, so that’s a pretty big priority too.
Feature wise, with the release of the final RFC, I expect HTTP/2 to be a very big topic in 2015.
And hopefully we will get to play more with new Perl features such as signatures, I can’t wait for a polyfill CPAN module to bring signatures to older versions of Perl.
NV: Finally, prompted by the news that Perl 6 will officially launch for production use by 2015, I’d like to hear your thoughts on Perl 6 and if it could or would be used, with or as part, of Mojolicious.
SR: I’ve had the pleasure to see Jonathan Worthington talk about concurrency and parallelism in Perl6 at Mojoconf 2014, and to say that it was quite inspiring would be an understatement.
But “production use” can mean a lot of different things to a lot of people. Is it feature complete? Is it as fast as Perl5? Would you bet the future of your company on it?
I love Perl6 the language, it solves all the problems I have with Perl5, and if there’s an implementation that’s good enough, you bet there will be a Mojolicious port!
Nikos Vaggalis has a BSc in Computer Science and a MSc in Interactive Multimedia. He works as a Database Developer with Linux and Ingres, and programs in both Perl and C#. As a journalist he writes articles, conducts interviews and reviews technical IT books

Our journey into the world of Perl’s Web frameworks would not be complete without Mojolicious, therefore we talked to Sebastian Riedel, Mojolicious’ mastermind and Catalyst’s original founder.
We looked at Mojolicious’ history: why Sebastian left Catalyst for Mojolicious, present: what does the framework actually do, the project’s future: Sebastian’s long-term plans, and whether Perl6 will have an effect on the project. We also get more technical with questions like why not opt for a DSL like Dancer does, what is meant by ‘real time web framework’, whether the framework is dependency free and much more.
NV: Do you think that now with Mojolicious, Catalyst and Dancer we are experiencing Perl’s newest and most successful Web revolution since the 90’s?
SR: It’s certainly a great time for web development with Perl, and it has been a lot of fun seeing Catalyst and Mojolicious take the Perl community by storm.
But for a real revolution, along the lines of CGI.pm in the late 90s, I think we have to get a lot better at reaching people outside the echo chamber, which is not really a technical, but a public relations problem.
NV: Why did you leave Catalyst for Mojolicious?
SR: Creative differences. At the time I was still experimenting a lot with new ideas for Catalyst, many of which are now part of Mojolicious, but what the majority of core team members really wanted was stability.
So rather than risk harming Catalyst with a drawn-out fight, I decided to leave for a fresh start.
It was very disappointing at the time, but the right decision in retrospect.
NV: Is Mojolicious a MVC framework and if so how does it implement the MVC pattern?
Yes, it is very similar to Catalyst in that regard. But we don’t highlight the fact very much, Model-View-Controller is just one of many design patterns we use.
Out of the box, Mojolicious is Model layer agnostic, and we consider web applications simply frontends to existing business logic. Controllers are plain old Perl classes, connecting this existing business logic to a View, which would usually be EP (Embedded Perl), or one of the many other template systems we support.
NV: There are many web frameworks out there each one targeting various areas of web development. Which ones does Mojolicious address and how does it compare to Dancer and Catalyst?
SR: There was a time when I would jump at every opportunity to learn more about all the different web frameworks out there, searching for inspiration.
But these days there’s actually very little innovation happening, almost all server-side frameworks follow the same basic formula.Some are trying to optimize for projects of a certain size, but it’s mostly just programming languages competing now.
So I only really pay attention to a very small number that is still experimenting with different architectures and technologies, usually written in languages other than Perl. Some recent examples would be Meteor (JavaScript) and Play Framework (Scala).
What’s really important to me with Mojolicious, and what I believe really differentiates it from everything else in Perl, is that we are always trying new things. Like we’ve done with tight integration of WebSockets and event loops, or the ability to grow from single-file prototypes to well structured web applications.
NV: What is the term ‘real time web framework’ referring to? To the capability of doing WebSockets, non-blocking I/O and event loops? Can you walk us through these concepts? Do such features make Mojolicious a prime platform for building Web APIs?
SR: The real-time web is simply a collection of technologies that allow content to be pushed to consumers with long-lived connections, as soon as it is generated. One of these technologies is the WebSocket protocol, offering full bi-directional low-latency communication channels between the browser and your web server.
I’m not actually a big fan of non-blocking I/O and event loops, but they are the tools that allow us to scale.So a single WebSocket server process can handle thousands of connections concurrently.
Sounds rather complicated, doesn’t it? But with Mojolicious all you need are these 9 lines of Perl code, and you have a fully functioning real-time web application :
use Mojolicious::Lite;
use 5.20.0;
use experimental 'signatures';
websocket '/echo' => sub ($c) {
$c->on(message => sub ($c, $msg) {
$c->send("echo: $msg");
});
};
app->start;
You tell me if this makes Mojolicious a “prime platform for building Web APIs”. :)
NV: How easy is to extend the framework with plugins and what are some of the most useful one?
Mojolicious has 415 reverse dependencies on MetaCPAN, so i’d say it is pretty easy to extend. While there are many many good ones, I have a weak spot for Mojolicious::Plugin::AssetPack, which takes care of all those annoying little asset management tasks, like minifying JavaScript and CSS files.
Mojolicious::Plugin::I18N and Mojolicious::Plugin::Mail are also very commonly used, and I guess I should mention my own Mojolicious::Plugin::Minion, which is a job queue designed specifically for Mojolicious.
In the next and final part, Sebastian shares his views on DSL’s, the project’s dependability and the upcoming release of Perl 6 for production use among others.
“In the end, Postgres looks to me like it’s saving us like 5X in hardware costs as we continue to grow.”
This comment was published on Redit about an article that compares PostgreSQL with MS SQL Server. I will not join the raging battle between the two clans and I am leaving the field to those who know best.
This article made me rethink the reasons why I like Open Source.
Why do I like Open Source?
This might be a very romantic view but I still believe people are good at working together for the benefit of our society. So what is Open Source? Open Source software is software whose code can be modified or enhanced by anyone.
Born from a grassroots movement, Open Source brings:
- Collaboration between people who may never meet but have the same vision
- Delivery of lower cost products as there are no big companies or shareholders behind the projects
- Strong motivation from individuals who have a huge interest in writing code, making other members of the community enthusiastic about their projects
- Flexibility as individuals make improvements which are then made available to the public
For all these reasons and a lot more, PostgreSQL is a good example of Open Source software and its movement. For example, 2ndQuadrant employees are significant contributors to the development of PostgreSQL with many of the features found in the current version developed by their people. Their latest addition is BDR (Bi-directional replication), an extension to PostgreSQL, free and Open Source which will be integrated to future versions of PostgreSQL.
Will Open Source saves us money? That I suppose will be the question for many years to come?
As mentioned in my last post, I went to CHAR(14). There I learnt about Bi-Directional Replication (BDR). BDR is an asynchronous multi-master replication system for PostgreSQL, specifically designed to allow geographically distributed clusters. Supporting up to 48 nodes (and possibly more in future releases) BDR is a low overhead, low maintenance technology for distributed databases.
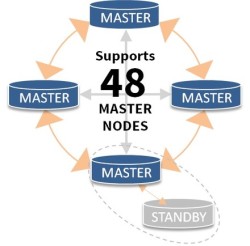
BDR is created by 2ndQuadrant and is the first of several replication technologies the company will announce this year to dramatically enhance PostgreSQL. Features of BDR have, and will continue to be moved into future releases of PostgreSQL. It is well-known that 2ndQuadrant develop code that all users of PostgreSQL can benefit from. The company has a long history of advancing the development of PostgreSQL, and specifically is accredited with making improvements to replication techniques.
2ndQuadrant’s CTO, Simon Riggs, commented: “BDR is a major enhancement to replication design and, with up to 48 master nodes supported, it offers a significant opportunity to reduce the overhead and headaches experienced with previous approaches to replication. For any organisation with distributed PostgreSQL databases replicated across multiple master nodes, BDR should be seriously considered.”
BDR is available as open source software, direct from 2ndQuadrant, with consultancy and support contracts available to ensure users can successfully design and implement a stable replicated environment. 2ndQuadrant’s Production Support service provides direct help from the development team behind BDR.
The company has been working with a number of early adopter clients, including BullionByPost®, and a leading antivirus software developer, to fine tune and evaluate BDR in demanding environments, ahead of this announcement.
I forgot to say that BDR, an extension to PostgreSQL, is free and open source; licensed under the same terms as PostgreSQL. PostgreSQL is released under the PostgreSQL License, a liberal Open Source license, similar to the BSD or MIT licenses.
You can get a lot more information on the website –
- Performance
- Start-up Guide
- BDR Documentation
- A chart comparing BDR to trigger-based replication solutions
There you can also describe your replication requirements or sign up for the quarterly Newsletter.